End-to-End LLM Evaluation
End-to-end evaluation assesses the "observable" inputs and outputs of your LLM application - it is what users see, and treats your LLM application as a black-box.
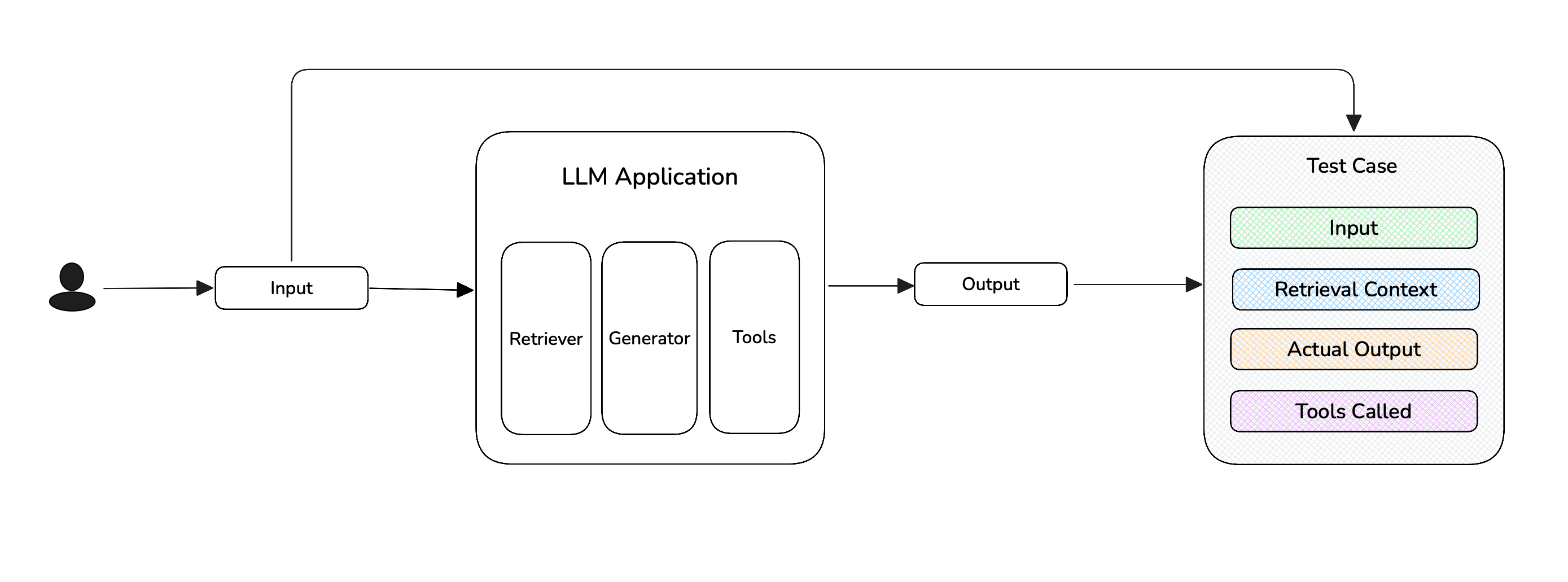
When should you run End-to-End evaluations?
For simple LLM applications like basic RAG pipelines with "flat" architectures
that can be represented by a single LLMTestCase, end-to-end
evaluation is ideal. Common use cases that are suitable for end-to-end
evaluation include (not inclusive):
- RAG QA
- PDF extraction
- Writing assitants
- Summarization
- etc.
You'll notice that use cases with simplier architectures are more suited for end-to-end evaluation. However, if your system is an extremely complex agentic workflow, you might also find end-to-end evaluation more suitable as you'll might conclude that that component-level evaluation gives you too much noise in its evaluation results.
Most of what you saw in DeepEval's quickstart is end-to-end evaluation!
What Are E2E Evals
Running an end-to-end LLM evaluation creates a test run — a collection of test cases that benchmarks your LLM application at a specific point in time. You would typically:
- Loop through a list of
Goldens - Invoke your LLM app with each golden's
input - Generate a set of test cases ready for evaluation
- Apply metrics to your test cases and run evaluations
To get a more fully sharable LLM test report login to Confident AI here or run the following in your terminal:
deepeval login
Setup Your Test Environment
Create a dataset
Datasets in deepeval allow you to store Goldens, which are like a precursors to test cases. They allow you to create test case dynamically during evaluation time by calling your LLM application. Here's how you can create goldens:
- Single-Turn
- Multi-Turn
from deepeval.dataset import Golden
goldens=[
Golden(input="What is your name?"),
Golden(input="Choose a number between 1 to 100"),
...
]
from deepeval.dataset import ConversationalGolden
goldens = [
ConversationalGolden(
scenario="Andy Byron wants to purchase a VIP ticket to a Coldplay concert.",
expected_outcome="Successful purchase of a ticket.",
user_description="Andy Byron is the CEO of Astronomer.",
),
...
]
You can also generate synthetic goldens automatically using the Synthesizer. Learn more here. You can now use these goldens to create an evaluation dataset that can be stored and loaded them anytime.
Here's an example showing how you can create and store datasets in deepeval:
- Confident AI
- Locally as CSV
- Locally as JSON
from deepeval.dataset import EvaluationDataset
dataset = EvaluationDataset(goldens)
dataset.push(alias="My dataset")
from deepeval.dataset import EvaluationDataset
dataset = EvaluationDataset(goldens)
dataset.save_as(
file_type="csv",
directory="./example"
)
from deepeval.dataset import EvaluationDataset
dataset = EvaluationDataset(goldens)
dataset.save_as(
file_type="json",
directory="./example"
)
✅ Done. You can now use this dataset anywhere to run your evaluations automatically by looping over them and generating test cases.
Select metrics
When it comes to selecting metrics for your application, we recommend choosing no more than 5 metrics, comprising of:
- (2 - 3) Generic metrics for your application type. (e.g. Agents, RAG, Chabot)
- (1 - 2) Custom metrics for your specific use case.
You can read our metrics section to learn about the 50+ metrics we offer. Or come to our discord and get some tailored recommendations from our team.
You can now use these test cases and metrics to run single-turn and multi-turn end-to-end evals. If you've setup tracing for your LLM application, you can automatically run end-to-end evals for traces using a single line of code.
Single-Turn E2E Evals
Load your dataset
deepeval offers support for loading datasets stored in JSON files, CSV files, and hugging face datasets into an EvaluationDataset as either test cases or goldens.
- Confident AI
- From CSV
- From JSON
from deepeval.dataset import EvaluationDataset
dataset = EvaluationDataset()
dataset.pull(alias="My Evals Dataset")
from deepeval.dataset import EvaluationDataset
dataset = EvaluationDataset()
dataset.add_goldens_from_csv_file(
# file_path is the absolute path to your .csv file
file_path="example.csv",
input_col_name="query"
)
from deepeval.dataset import EvaluationDataset
dataset = EvaluationDataset()
dataset.add_goldens_from_json_file(
# file_path is the absolute path to your .json file
file_path="example.json",
input_key_name="query"
)
Create test cases using dataset
You can now create LLMTestCases using the goldens by calling your LLM application.
from your_agent import your_llm_app # Replace with your LLM app
from deepeval.dataset import EvaluationDataset
from deepeval.test_case import LLMTestCase
dataset = EvaluationDataset()
test_cases = []
# Create test cases from goldens
for golden in dataset.goldens:
res, text_chunks = your_llm_app(golden.input)
test_case = LLMTestCase(input=golden.input, actual_output=res, retrieval_context=text_chunks)
test_cases.append(test_case)
You can also add test cases directly into your dataset by using the add_test_case() method.
Run end-to-end evals
You should pass the test_cases and metrics you've decided in the evaluate() function to run end-to-end evals.
from your_agent import your_llm_app # Replace with your LLM app
from deepeval.metrics import AnswerRelevancyMetric
from deepeval import evaluate
...
evaluate(
test_cases=test_cases,
metrics=[AnswerRelevancyMetric()],
hyperparameters={
model="gpt-4.1",
system_prompt="..."
}
)
There are TWO mandatory and SIX optional parameters when calling the evaluate() function for END-TO-END evaluation:
test_cases: a list ofLLMTestCases ORConversationalTestCases, or anEvaluationDataset. You cannot evaluateLLMTestCases andConversationalTestCases in the same test run.metrics: a list of metrics of typeBaseMetric.- [Optional]
hyperparameters: a dict of typedict[str, Union[str, int, float]]. You can log any arbitrary hyperparameter associated with this test run to pick the best hyperparameters for your LLM application on Confident AI. - [Optional]
identifier: a string that allows you to better identify your test run on Confident AI. - [Optional]
async_config: an instance of typeAsyncConfigthat allows you to customize the degree of concurrency during evaluation. Defaulted to the defaultAsyncConfigvalues. - [Optional]
display_config:an instance of typeDisplayConfigthat allows you to customize what is displayed to the console during evaluation. Defaulted to the defaultDisplayConfigvalues. - [Optional]
error_config: an instance of typeErrorConfigthat allows you to customize how to handle errors during evaluation. Defaulted to the defaultErrorConfigvalues. - [Optional]
cache_config: an instance of typeCacheConfigthat allows you to customize the caching behavior during evaluation. Defaulted to the defaultCacheConfigvalues.
This is exactly the same as assert_test() in deepeval test run, but in a different interface.
We recommend logging your hyperparameters during your evauations as they allow you find the best model configuration for your application.
Multi-Turn E2E Evals
Wrap chatbot in callback
You need to define a chatbot callback to generate synthetic test cases from goldens using the ConversationSimulator. So, define a callback function to generate the next chatbot response in a conversation, given the conversation history.
- Python
- OpenAI
- LangChain
- LlamaIndex
- OpenAI Agents
- Pydantic
from deepeval.test_case import Turn
async def model_callback(input: str, turns: List[Turn], thread_id: str) -> Turn:
# Replace with your chatbot
response = await your_chatbot(input, turns, thread_id)
return Turn(role="assistant", content=response)
from deepeval.test_case import Turn
from openai import OpenAI
client = OpenAI()
async def model_callback(input: str, turns: List[Turn]) -> str:
messages = [
{"role": "system", "content": "You are a ticket purchasing assistant"},
*[{"role": t.role, "content": t.content} for t in turns],
{"role": "user", "content": input},
]
response = await client.chat.completions.create(model="gpt-4.1", messages=messages)
return Turn(role="assistant", content=response.choices[0].message.content)
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_community.chat_message_histories import ChatMessageHistory
store = {}
llm = ChatOpenAI(model="gpt-4")
prompt = ChatPromptTemplate.from_messages([("system", "You are a ticket purchasing assistant."), MessagesPlaceholder(variable_name="history"), ("human", "{input}")])
chain_with_history = RunnableWithMessageHistory(prompt | llm, lambda session_id: store.setdefault(session_id, ChatMessageHistory()), input_messages_key="input", history_messages_key="history")
async def model_callback(input: str, thread_id: str) -> Turn:
response = chain_with_history.invoke(
{"input": input},
config={"configurable": {"session_id": thread_id}}
)
return Turn(role="assistant", content=response.content)
from llama_index.core.storage.chat_store import SimpleChatStore
from llama_index.llms.openai import OpenAI
from llama_index.core.chat_engine import SimpleChatEngine
from llama_index.core.memory import ChatMemoryBuffer
chat_store = SimpleChatStore()
llm = OpenAI(model="gpt-4")
async def model_callback(input: str, thread_id: str) -> Turn:
memory = ChatMemoryBuffer.from_defaults(chat_store=chat_store, chat_store_key=thread_id)
chat_engine = SimpleChatEngine.from_defaults(llm=llm, memory=memory)
response = chat_engine.chat(input)
return Turn(role="assistant", content=response.response)
from agents import Agent, Runner, SQLiteSession
sessions = {}
agent = Agent(name="Test Assistant", instructions="You are a helpful assistant that answers questions concisely.")
async def model_callback(input: str, thread_id: str) -> Turn:
if thread_id not in sessions:
sessions[thread_id] = SQLiteSession(thread_id)
session = sessions[thread_id]
result = await Runner.run(agent, input, session=session)
return Turn(role="assistant", content=result.final_output)
from pydantic_ai.messages import ModelRequest, ModelResponse, UserPromptPart, TextPart
from deepeval.test_case import Turn
from datetime import datetime
from pydantic_ai import Agent
from typing import List
agent = Agent('openai:gpt-4', system_prompt="You are a helpful assistant that answers questions concisely.")
async def model_callback(input: str, turns: List[Turn]) -> Turn:
message_history = []
for turn in turns:
if turn.role == "user":
message_history.append(ModelRequest(parts=[UserPromptPart(content=turn.content, timestamp=datetime.now())], kind='request'))
elif turn.role == "assistant":
message_history.append(ModelResponse(parts=[TextPart(content=turn.content)], model_name='gpt-4', timestamp=datetime.now(), kind='response'))
result = await agent.run(input, message_history=message_history)
return Turn(role="assistant", content=result.output)
Your model callback should accept an input, and optionally turns and thread_id. It should return a Turn object.
Load your dataset
deepeval offers support for loading datasets stored in JSON files, CSV files, and hugging face datasets into an EvaluationDataset as either test cases or goldens.
- Confident AI
- From JSON
- From CSV
from deepeval.dataset import EvaluationDataset
dataset = EvaluationDataset()
dataset.pull(alias="My Evals Dataset")
from deepeval.dataset import EvaluationDataset
dataset = EvaluationDataset()
dataset.add_goldens_from_json_file(
# file_path is the absolute path to your .json file
file_path="example.json",
input_key_name="query"
)
from deepeval.dataset import EvaluationDataset
dataset = EvaluationDataset()
dataset.add_goldens_from_csv_file(
# file_path is the absolute path to your .csv file
file_path="example.csv",
input_col_name="query"
)
Simulate turns
Use deepeval's ConversationSimulator to simulate turns using goldens in your dataset:
from deepeval.conversation_simulator import ConversationSimulator
simulator = ConversationSimulator(model_callback=chatbot_callback)
conversational_test_cases = simulator.simulate(goldens=dataset.goldens, max_turns=10)
Here, we only have 1 test case, but in reality you'll want to simulate from at least 20 goldens.
Click to view an example simulated test case
Your generated test cases should be populated with simulated Turns, along with the scenario, expected_outcome, and user_description from the conversation golden.
ConversationalTestCase(
scenario="Andy Byron wants to purchase a VIP ticket to a Coldplay concert.",
expected_outcome="Successful purchase of a ticket.",
user_description="Andy Byron is the CEO of Astronomer.",
turns=[
Turn(role="user", content="Hello, how are you?"),
Turn(role="assistant", content="I'm doing well, thank you!"),
Turn(role="user", content="How can I help you today?"),
Turn(role="assistant", content="I'd like to buy a ticket to a Coldplay concert."),
]
)
Run an evaluation
Run an evaluation like how you learnt in the previous section:
from deepeval.metrics import TurnRelevancyMetric
from deepeval import evaluate
...
evaluate(
conversational_test_cases,
metrics=[TurnRelevancyMetric()],
hyperparameters={
model="gpt-4.1",
system_prompt="..."
}
)
There are TWO mandatory and SIX optional parameters when calling the evaluate() function for END-TO-END evaluation:
test_cases: a list ofLLMTestCases ORConversationalTestCases, or anEvaluationDataset. You cannot evaluateLLMTestCases andConversationalTestCases in the same test run.metrics: a list of metrics of typeBaseConversationalMetric.- [Optional]
hyperparameters: a dict of typedict[str, Union[str, int, float]]. You can log any arbitrary hyperparameter associated with this test run to pick the best hyperparameters for your LLM application on Confident AI. - [Optional]
identifier: a string that allows you to better identify your test run on Confident AI. - [Optional]
async_config: an instance of typeAsyncConfigthat allows you to customize the degree of concurrency during evaluation. Defaulted to the defaultAsyncConfigvalues. - [Optional]
display_config:an instance of typeDisplayConfigthat allows you to customize what is displayed to the console during evaluation. Defaulted to the defaultDisplayConfigvalues. - [Optional]
error_config: an instance of typeErrorConfigthat allows you to customize how to handle errors during evaluation. Defaulted to the defaultErrorConfigvalues. - [Optional]
cache_config: an instance of typeCacheConfigthat allows you to customize the caching behavior during evaluation. Defaulted to the defaultCacheConfigvalues.
This is exactly the same as assert_test() in deepeval test run, but in a difference interface.
We highly recommend setting up Confident AI with your deepeval evaluations to get professional test reports and observe trends of your LLM application's performance overtime like this:
E2E Evals For Tracing
If you've setup tracing for you LLM application, you can run end-to-end evals using the evals_iterator() function.
Load your dataset
deepeval offers support for loading datasets stored in JSON files, CSV files, and hugging face datasets into an EvaluationDataset as either test cases or goldens.
- Confident AI
- From CSV
- From JSON
from deepeval.dataset import EvaluationDataset
dataset = EvaluationDataset()
dataset.pull(alias="My Evals Dataset")
from deepeval.dataset import EvaluationDataset
dataset = EvaluationDataset()
dataset.add_goldens_from_csv_file(
# file_path is the absolute path to your .csv file
file_path="example.csv",
input_col_name="query"
)
from deepeval.dataset import EvaluationDataset
dataset = EvaluationDataset()
dataset.add_goldens_from_json_file(
# file_path is the absolute path to your .json file
file_path="example.json",
input_key_name="query"
)
Update your test cases for trace
You can update your end-to-end test cases for trace by using the update_current_trace function provided by deepeval
from openai import OpenAI
from deepeval.tracing import observe, update_current_trace
@observe()
def llm_app(query: str) -> str:
@observe()
def retriever(query: str) -> list[str]:
chunks = ["List", "of", "text", "chunks"]
update_current_trace(retrieval_context=chunks)
return chunks
@observe()
def generator(query: str, text_chunks: list[str]) -> str:
res = OpenAI().chat.completions.create(model="gpt-4o", messages=[{"role": "user", "content": query}]
).choices[0].message.content
update_current_trace(input=query, output=res)
return res
return generator(query, retriever(query))
There are TWO ways to create test cases when using the update_current_trace function:
-
[Optional]
test_case: Takes anLLMTestCaseto create a span level test case for that component. -
Or, You can also opt to give the values of
LLMTestCasedirectly by using the following attributes:- [Optional]
input - [Optional]
output - [Optional]
retrieval_context - [Optional]
context - [Optional]
expected_output - [Optional]
tools_called - [Optional]
expected_tools
- [Optional]
You can use the individual LLMTestCase params in the update_current_trace function to override the values of the test_case you passed.
Run end-to-end evals
You can run end-to-end evals for your traces by supplying your metrics in the evals_iterator function.
from deepeval.metrics import AnswerRelevancyMetric
from deepeval.dataset import EvaluationDataset
dataset = EvaluationDataset()
dataset.pull(alias="YOUR-DATASET-ALIAS")
for golden in dataset.evals_iterator(metrics=[AnswerRelevancyMetric()]):
llm_app(golden.input) # Replace with your LLM app
There are SIX optional parameters when using the evals_iterator():
- [Optional]
metrics: a list ofBaseMetricthat allows you to run end-to-end evals for your traces. - [Optional]
identifier: a string that allows you to better identify your test run on Confident AI. - [Optional]
async_config: an instance of typeAsyncConfigthat allows you to customize the degree concurrency during evaluation. Defaulted to the defaultAsyncConfigvalues. - [Optional]
display_config:an instance of typeDisplayConfigthat allows you to customize what is displayed to the console during evaluation. Defaulted to the defaultDisplayConfigvalues. - [Optional]
error_config: an instance of typeErrorConfigthat allows you to customize how to handle errors during evaluation. Defaulted to the defaultErrorConfigvalues. - [Optional]
cache_config: an instance of typeCacheConfigthat allows you to customize the caching behavior during evaluation. Defaulted to the defaultCacheConfigvalues.
This is all it takes to run end-to-end evaluations, with the added benefit of a full testing report with tracing included on Confident AI.
If you want to run end-to-end evaluations in CI/CD piplines, click here.